Para completar este trabajo mostramos un código que nos ayuda a encontrar una politica óptima. Esto lo haremos estimando los parametros definidos en la sección Capítulo 2 para los 4 equipos (Chivas, América, Cruz Azul).
5.1 Club Deportido Guadalajara
Según datos extraídos de FBREF obtenemos los siguientes parámetros:
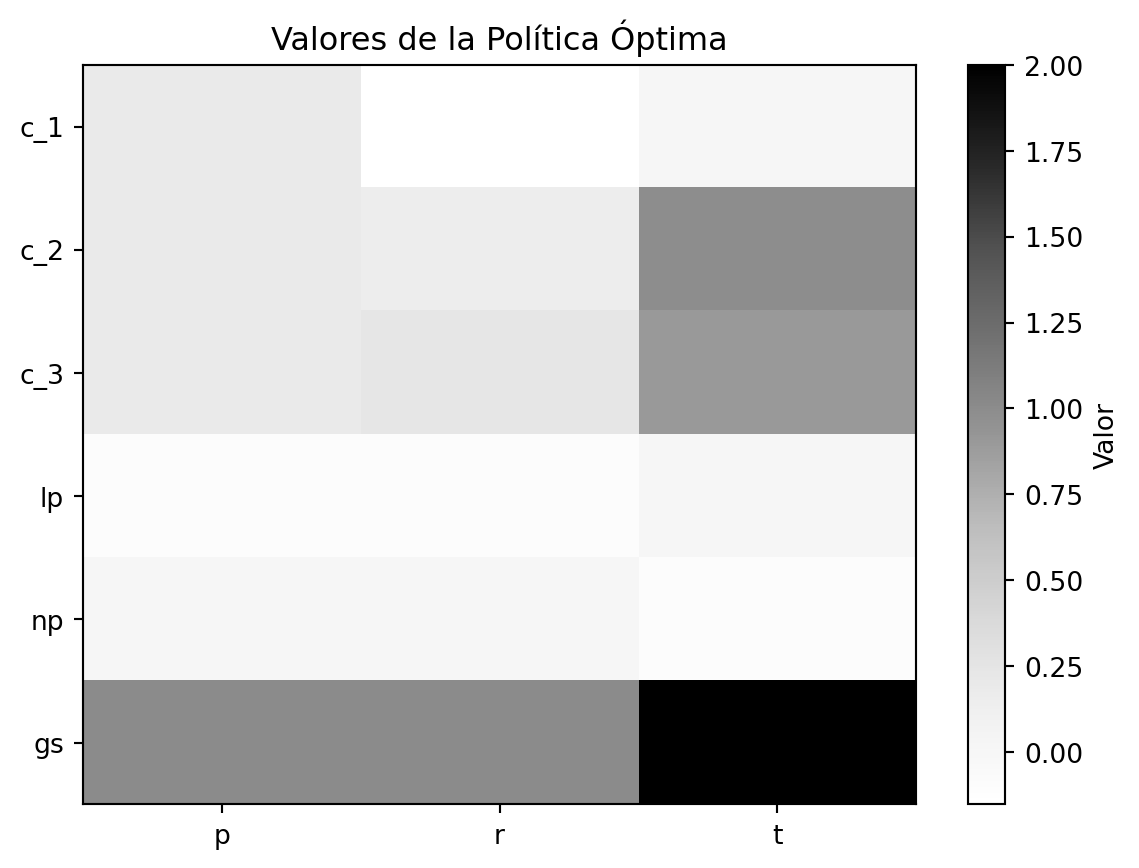
Con esto podemos obtener la política óptima. Además por motivos de simulación agregamos ciertos costo y recompensas para cada estado dependiendo de la acción, esto se me modificará
Código
import numpy as np import matplotlib.pyplot as plt# Parámetros de transición y recompensas# C_1alpha_1p =0.43alpha_2p =0.23alpha_3p =0.12alpha_4p =0.22alpha_1r =0.28alpha_2r =0.20alpha_3r =0.52# C_2beta_1p =0.34beta_2p =0.21beta_3p =0.14beta_4p =0.31beta_1r =0.20beta_2r =0.12beta_3r =0.07beta_4r =0.61beta_1t =0.01beta_2t =0.99# C_3gamma_1p =0.05gamma_2p =0.47gamma_3p =0.18gamma_4p =0.30gamma_1r =0.14gamma_2r =0.08gamma_3r =0.78gamma_1t =0.10gamma_2t =0.90# Estados y accionesstates = ['c_1','c_2','c_3','lp','np','gs']actions = ['p','r','t']rewards = {'c_1':{'p':0.1,'r':-0.2,'t':0},'c_2':{'p':0.1,'r':0.1,'t':0},'c_3':{'p':0.1,'r':0.2,'t':0},'lp':{'p':-0.1,'r':-0.1,'t':0},'np':{'p':0,'r':0,'t':-0.1},'gs':{'p':0,'r':0,'t':1}}transition = {'c_1':{'p':{'c_1':alpha_1p,'c_2':alpha_2p,'c_3':alpha_3p,'lp':alpha_4p,'np':0,'gs':0},'r':{'c_1':alpha_1r,'c_2':alpha_2r,'c_3':0,'lp':alpha_3r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':0}},'c_2':{'p':{'c_1':beta_1p,'c_2':beta_2p,'c_3':beta_3p,'lp':beta_4p,'np':0,'gs':0},'r':{'c_1':beta_1r,'c_2':beta_2r,'c_3':beta_3r,'lp':beta_4r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':beta_1t,'gs':beta_2t}},'c_3':{'p':{'c_1':gamma_1p,'c_2':gamma_2p,'c_3':gamma_3p,'lp':gamma_4p,'np':0,'gs':0},'r':{'c_1':0,'c_2':gamma_1r,'c_3':gamma_2r,'lp':gamma_3r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':gamma_1t,'gs':gamma_2t}},'lp':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0}},'np':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0}},'gs':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1}}}# Función para Value Iterationdef value_iteration(): V = {s: 0for s in states} cont =0while (Trueand cont<10000): new_V = {}for s in states: values = []for a in actions: value = rewards[s][a]for s2 in states: value += transition[s][a][s2] * V[s2]#print(value) values.append(value)#print(values) new_V[s]=max(values)#print(f'nuevo vector {new_V}')ifall(abs(V[s]-new_V[s])<0.0001for s in states):return new_V cont = cont +1 V = new_Vreturn VV = value_iteration() # Política óptimapolicy = {}for s in states: values = []for a in actions: value = rewards[s][a]for s2 in states: value+= transition[s][a][s2] * V[s2] values.append(value) policy[s] = actions[np.argmax(values)]print('Política Óptima')print(policy)# Visualización de los valores de políticapolicy_values = np.zeros((len(states),len(actions)))for i, s inenumerate(states):for j, a inenumerate(actions): policy_values[i, j] = rewards[s][a] +sum(transition[s][a][s2] * V[s2] for s2 in states)plt.imshow(policy_values, cmap="Greys", aspect="auto")plt.xticks(ticks=range(len(actions)), labels=actions)plt.yticks(ticks=range(len(states)), labels=states)plt.colorbar(label="Valor")plt.title("Valores de la Política Óptima")plt.show()
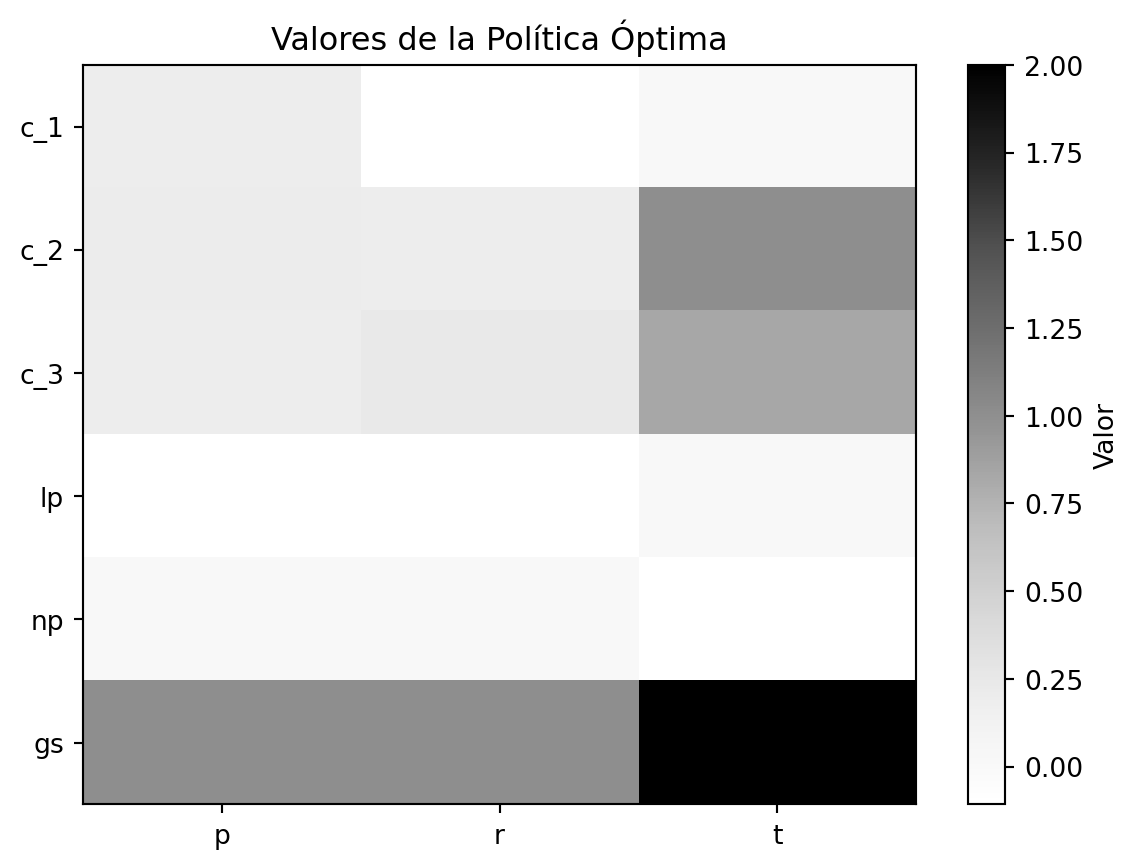
Con esto podemos obtener la política óptima. Además por motivos de simulación agregamos ciertos costo y recompensas para cada estado dependiendo de la acción.
Código
import numpy as np import matplotlib.pyplot as plt# Parámetros de transición y recompensas# C_1alpha_1p =0.59alpha_2p =0.27alpha_3p =0.02alpha_4p =0.12alpha_1r =0.54alpha_2r =0.39alpha_3r =0.07# C_2beta_1p =0.31beta_2p =0.45beta_3p =0.12beta_4p =0.12beta_1r =0.29beta_2r =0.24beta_3r =0.16beta_4r =0.31beta_1t =0.004beta_2t =0.996# C_3gamma_1p =0.09gamma_2p =0.58gamma_3p =0.10gamma_4p =0.23gamma_1r =0.14gamma_2r =0.10gamma_3r =0.76gamma_1t =0.17gamma_2t =0.83# Estados y accionesstates = ['c_1','c_2','c_3','lp','np','gs']actions = ['p','r','t']rewards = {'c_1':{'p':0.1,'r':-0.2,'t':0},'c_2':{'p':0.1,'r':0.1,'t':0},'c_3':{'p':0.1,'r':0.2,'t':0},'lp':{'p':-0.1,'r':-0.1,'t':0},'np':{'p':0,'r':0,'t':-0.1},'gs':{'p':0,'r':0,'t':1}}transition = {'c_1':{'p':{'c_1':alpha_1p,'c_2':alpha_2p,'c_3':alpha_3p,'lp':alpha_4p,'np':0,'gs':0},'r':{'c_1':alpha_1r,'c_2':alpha_2r,'c_3':0,'lp':alpha_3r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':0}},'c_2':{'p':{'c_1':beta_1p,'c_2':beta_2p,'c_3':beta_3p,'lp':beta_4p,'np':0,'gs':0},'r':{'c_1':beta_1r,'c_2':beta_2r,'c_3':beta_3r,'lp':beta_4r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':beta_1t,'gs':beta_2t}},'c_3':{'p':{'c_1':gamma_1p,'c_2':gamma_2p,'c_3':gamma_3p,'lp':gamma_4p,'np':0,'gs':0},'r':{'c_1':0,'c_2':gamma_1r,'c_3':gamma_2r,'lp':gamma_3r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':gamma_1t,'gs':gamma_2t}},'lp':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0}},'np':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0}},'gs':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1}}}# Función para Value Iterationdef value_iteration(): V = {s: 0for s in states} cont =0while (Trueand cont<10000): new_V = {}for s in states: values = []for a in actions: value = rewards[s][a]for s2 in states: value += transition[s][a][s2] * V[s2]#print(value) values.append(value)#print(values) new_V[s]=max(values)#print(f'nuevo vector {new_V}')ifall(abs(V[s]-new_V[s])<0.0001for s in states):return new_V cont = cont +1 V = new_Vreturn VV = value_iteration() # Política óptimapolicy = {}for s in states: values = []for a in actions: value = rewards[s][a]for s2 in states: value+= transition[s][a][s2] * V[s2] values.append(value) policy[s] = actions[np.argmax(values)]print('Política Óptima')print(policy)# Visualización de los valores de políticapolicy_values = np.zeros((len(states),len(actions)))for i, s inenumerate(states):for j, a inenumerate(actions): policy_values[i, j] = rewards[s][a] +sum(transition[s][a][s2] * V[s2] for s2 in states)plt.imshow(policy_values, cmap="Greys", aspect="auto")plt.xticks(ticks=range(len(actions)), labels=actions)plt.yticks(ticks=range(len(states)), labels=states)plt.colorbar(label="Valor")plt.title("Valores de la Política Óptima")plt.show()
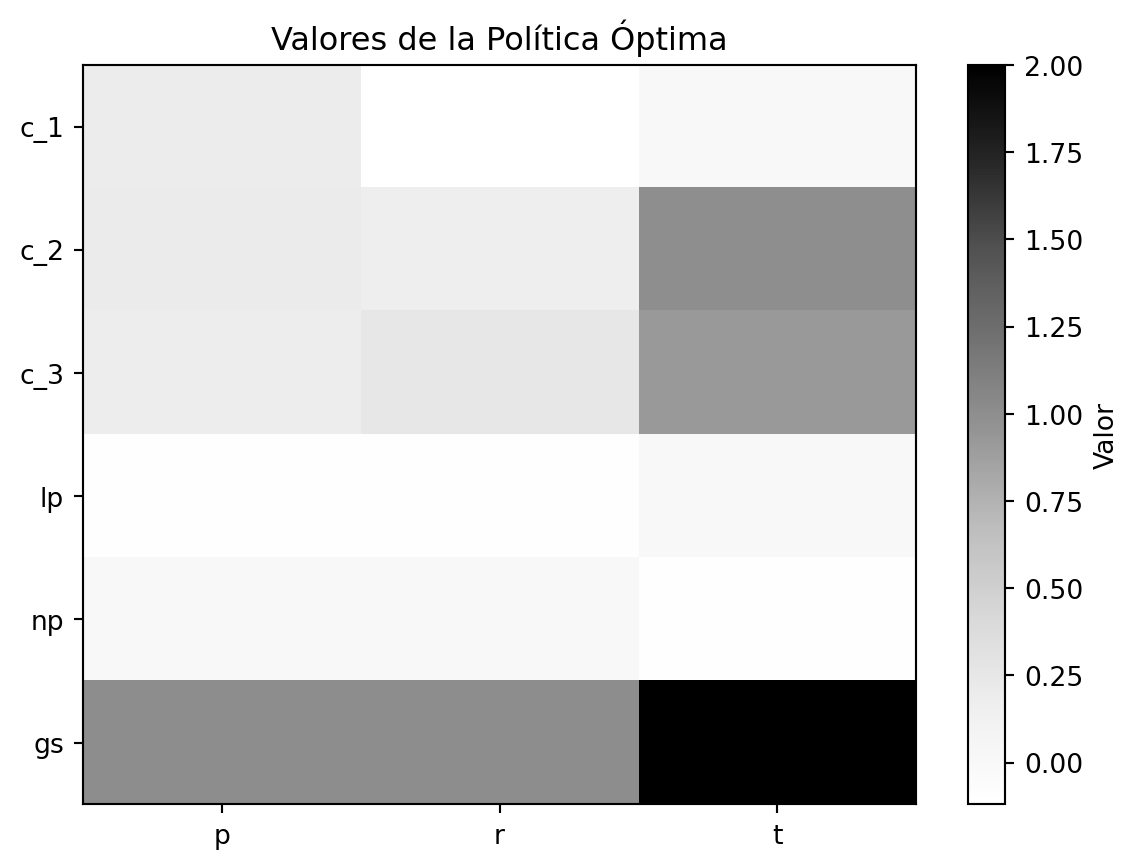
Con esto podemos obtener la política óptima. Además por motivos de simulación agregamos ciertos costo y recompensas para cada estado dependiendo de la acción.
Código
import numpy as np import matplotlib.pyplot as plt# Parámetros de transición y recompensas# C_1alpha_1p =0.63alpha_2p =0.28alpha_3p =0.01alpha_4p =0.08alpha_1r =0.52alpha_2r =0.29alpha_3r =0.19# C_2beta_1p =0.41beta_2p =0.33beta_3p =0.12beta_4p =0.14beta_1r =0.19beta_2r =0.28beta_3r =0.11beta_4r =0.52beta_1t =0.009beta_2t =0.991# C_3gamma_1p =0.10gamma_2p =0.37gamma_3p =0.19gamma_4p =0.34gamma_1r =0.21gamma_2r =0.09gamma_3r =0.70gamma_1t =0.08gamma_2t =0.92# Estados y accionesstates = ['c_1','c_2','c_3','lp','np','gs']actions = ['p','r','t']rewards = {'c_1':{'p':0.1,'r':-0.2,'t':0},'c_2':{'p':0.1,'r':0.1,'t':0},'c_3':{'p':0.1,'r':0.2,'t':0},'lp':{'p':-0.1,'r':-0.1,'t':0},'np':{'p':0,'r':0,'t':-0.1},'gs':{'p':0,'r':0,'t':1}}transition = {'c_1':{'p':{'c_1':alpha_1p,'c_2':alpha_2p,'c_3':alpha_3p,'lp':alpha_4p,'np':0,'gs':0},'r':{'c_1':alpha_1r,'c_2':alpha_2r,'c_3':0,'lp':alpha_3r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':0}},'c_2':{'p':{'c_1':beta_1p,'c_2':beta_2p,'c_3':beta_3p,'lp':beta_4p,'np':0,'gs':0},'r':{'c_1':beta_1r,'c_2':beta_2r,'c_3':beta_3r,'lp':beta_4r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':beta_1t,'gs':beta_2t}},'c_3':{'p':{'c_1':gamma_1p,'c_2':gamma_2p,'c_3':gamma_3p,'lp':gamma_4p,'np':0,'gs':0},'r':{'c_1':0,'c_2':gamma_1r,'c_3':gamma_2r,'lp':gamma_3r,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':gamma_1t,'gs':gamma_2t}},'lp':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':1,'np':0,'gs':0}},'np':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':1,'gs':0}},'gs':{'p':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1},'r':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1},'t':{'c_1':0,'c_2':0,'c_3':0,'lp':0,'np':0,'gs':1}}}# Función para Value Iterationdef value_iteration(): V = {s: 0for s in states} cont =0while (Trueand cont<10000): new_V = {}for s in states: values = []for a in actions: value = rewards[s][a]for s2 in states: value += transition[s][a][s2] * V[s2]#print(value) values.append(value)#print(values) new_V[s]=max(values)#print(f'nuevo vector {new_V}')ifall(abs(V[s]-new_V[s])<0.0001for s in states):return new_V cont = cont +1 V = new_Vreturn VV = value_iteration() # Política óptimapolicy = {}for s in states: values = []for a in actions: value = rewards[s][a]for s2 in states: value+= transition[s][a][s2] * V[s2] values.append(value) policy[s] = actions[np.argmax(values)]print('Política Óptima')print(policy)# Visualización de los valores de políticapolicy_values = np.zeros((len(states),len(actions)))for i, s inenumerate(states):for j, a inenumerate(actions): policy_values[i, j] = rewards[s][a] +sum(transition[s][a][s2] * V[s2] for s2 in states)plt.imshow(policy_values, cmap="Greys", aspect="auto")plt.xticks(ticks=range(len(actions)), labels=actions)plt.yticks(ticks=range(len(states)), labels=states)plt.colorbar(label="Valor")plt.title("Valores de la Política Óptima")plt.show()